A model that runs in a notebook tells you nothing about whether it can fly. On a CubeSat the real constraints are kilobytes of flash, a fixed power budget, and a flight computer that cannot phone home for a GPU. This post takes a trained model, shrinks it with int8 quantization, measures what that actually costs in size and accuracy, and lays out the bench setup for the part that matters most in orbit: power.
This is the hardware-facing side of the work I care about. Not just the model, but how the model behaves once it has to fit and run inside a strict budget.
A model sized for a microcontroller
I trained a small 1D-CNN that classifies 64-band reflectance spectra into four asteroid-like complexes, the same shape of problem as the asteroid classifier but deliberately compact. It has 33,524 parameters. In float32 that is about 130 KB of weights, which already fits comfortably in the flash of a mid-range microcontroller, but float weights also mean float math, and many MCUs have no FPU.
Quantizing to int8
Quantization maps the float weights and activations onto 8-bit integers, so the model is a quarter of the size and the arithmetic is integer-only. I export the trained network to ONNX and run full int8 static quantization, calibrating the activation ranges on training spectra. This is the same post-training quantization a TensorFlow Lite Micro deployment does.
quantize_static(FP32, INT8, Calib(Xtr), quant_format=QuantFormat.QDQ,
weight_type=QuantType.QInt8, activation_type=QuantType.QInt8,
per_channel=False)
What changed
Running both models through ONNX Runtime on the same test set:
parameters: 33524
fp32 onnx: 132.4 KB int8 onnx: 39.9 KB (3.3x smaller)
accuracy fp32 0.978 int8 0.964 (drop 1.4 pts)
latency fp32 10.5 us int8 8.2 us (per inference, desktop CPU)
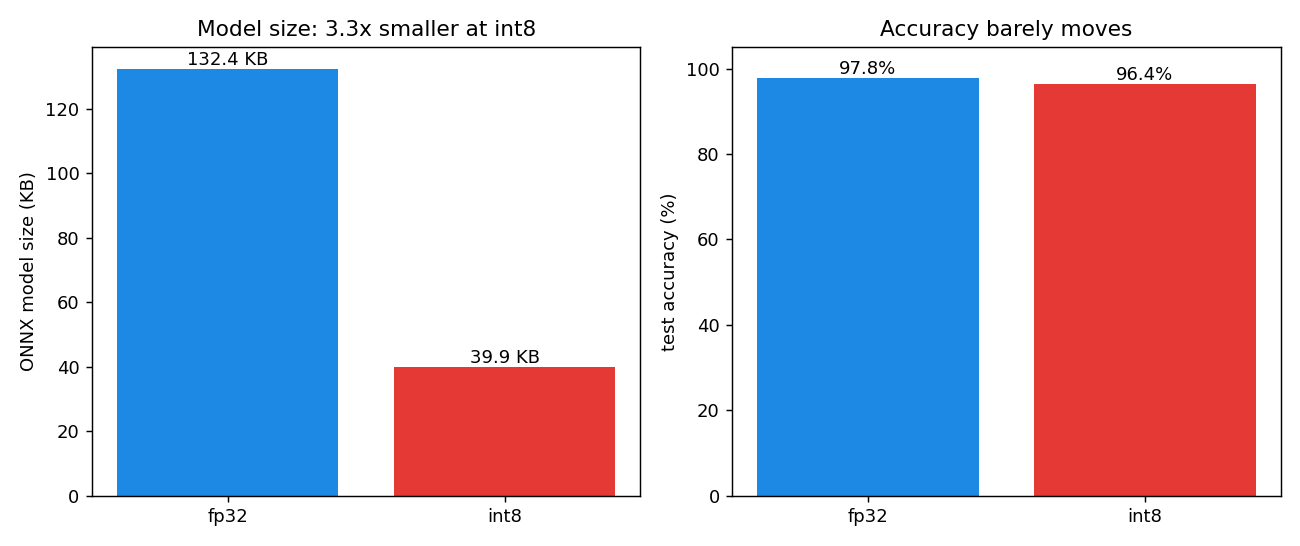
The size dropped by 3.3x rather than the full 4x you might expect from 32-bit to 8-bit, and the reason is worth knowing. The weight tensors really do shrink 4x, from about 130 KB to 33 KB, but the int8 ONNX file also carries the quantize and dequantize nodes plus their scale and zero-point constants, and that graph overhead eats into the saving. On a model this small the overhead is visible; on a larger one it is noise. The number that matters for flash is the weight footprint, and that is the clean 4x.
Accuracy fell by 1.4 points, which is the usual quantization tax and is recoverable with quantization-aware training if you need it. Latency dropped a little on the desktop, but that is not where the int8 win lives. On a desktop with a fast FPU, float and int8 are close. On an MCU with no FPU, integer math is the difference between a model that runs and one that does not.
Onto the bench: measuring the real cost
The size and accuracy numbers above I can get anywhere. The number that decides whether this flies, energy per inference, only exists on real hardware, so this is where the software story hands off to the bench.
The plan is the periodic-task shape from my Pulse scheduler post: the int8 model runs inside one bounded, periodic task under FreeRTOS, statically allocated, with the inference triggered on a fixed cadence.
// inference task: read one spectrum, run the int8 model, publish the class
void infer_task(void *arg) {
for (;;) {
read_spectrum(buf);
int cls = tinyml_invoke(buf); // int8 interpreter, no heap
publish(cls);
vTaskDelay(period);
}
}
The measurement is an INA219 inline on the supply, logging current during idle and during inference. Energy per inference is current times voltage times the inference duration, and the three things I want off that trace are the energy per inference, the peak draw, and how that peak sits against the power budget. A model that triples peak draw during a sun-pointing maneuver is a mission problem, not a software detail, and the only way to know is to measure it. I will post that trace once it is on the bench.
Mission assurance
Onboard inference is what buys autonomy without a ground link, but autonomy you cannot bound is a liability. Quantization error, worst-case execution time, peak current: these are things you certify before launch, not things you hope about afterward. That is the whole gap between a model that works in a notebook and code that is allowed to fly, and closing it is the kind of work I want the lab built around.
Full code
#!/usr/bin/env python
"""TinyML: int8 quantization of a small spectrum classifier.
Train a compact 1D-CNN that classifies 64-band reflectance spectra into four
asteroid-like complexes, export it to ONNX, then quantize it to full int8 with
ONNX Runtime (the same post-training quantization a microcontroller deployment
uses). Report the real size, accuracy, and latency before and after.
"""
import os
import time
import numpy as np
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import onnxruntime as ort
from onnxruntime.quantization import (quantize_static, QuantType, QuantFormat,
CalibrationDataReader)
rng = np.random.default_rng(0)
torch.manual_seed(0)
RES = "res"
FP32 = os.path.join(RES, "spectrum_fp32.onnx")
INT8 = os.path.join(RES, "spectrum_int8.onnx")
N_BAND, N_CLASS = 64, 4
# ---------------------------------------------------------------------------
# synthetic 64-band reflectance spectra for 4 broad complexes
# ---------------------------------------------------------------------------
bands = np.linspace(0, 1, N_BAND)
def spectrum(cls):
if cls == 0: # S: red slope, shallow 1 um band
s = 0.8 + 0.5 * bands - 0.15 * np.exp(-((bands - 0.6) / 0.12) ** 2)
elif cls == 1: # C: flat and dark
s = 0.55 + 0.05 * bands
elif cls == 2: # X: flat, brighter
s = 0.85 + 0.1 * bands
else: # V: strong 1 um absorption
s = 0.9 + 0.4 * bands - 0.4 * np.exp(-((bands - 0.65) / 0.1) ** 2)
s = s + rng.normal(0, 0.03, N_BAND)
return (s / s.max()).astype(np.float32)
def make(n):
X, y = [], []
for _ in range(n):
c = rng.integers(0, N_CLASS)
X.append(spectrum(c)); y.append(c)
return np.array(X, np.float32)[:, None, :], np.array(y, np.int64)
Xtr, ytr = make(4000)
Xte, yte = make(1000)
# ---------------------------------------------------------------------------
# a compact 1D-CNN (MCU-sized)
# ---------------------------------------------------------------------------
class SpectrumNet(nn.Module):
def __init__(self):
super().__init__()
self.net = nn.Sequential(
nn.Conv1d(1, 8, 3, padding=1), nn.ReLU(),
nn.Conv1d(8, 16, 3, padding=1), nn.ReLU(),
nn.MaxPool1d(2), nn.Flatten(),
nn.Linear(16 * (N_BAND // 2), 64), nn.ReLU(),
nn.Linear(64, N_CLASS))
def forward(self, x):
return self.net(x)
net = SpectrumNet()
opt = torch.optim.Adam(net.parameters(), lr=2e-3)
lossf = nn.CrossEntropyLoss()
xt, yt = torch.tensor(Xtr), torch.tensor(ytr)
for epoch in range(30):
perm = torch.randperm(len(yt))
for i in range(0, len(yt), 128):
b = perm[i:i + 128]
opt.zero_grad()
loss = lossf(net(xt[b]), yt[b])
loss.backward()
opt.step()
net.eval()
n_params = sum(p.numel() for p in net.parameters())
print(f"[tinyml] model parameters: {n_params}")
# export fp32 ONNX (legacy exporter, no onnxscript dependency)
torch.onnx.export(net, torch.tensor(Xte[:1]), FP32,
input_names=["spectrum"], output_names=["logits"],
dynamic_axes={"spectrum": {0: "batch"}, "logits": {0: "batch"}},
opset_version=13, dynamo=False)
# int8 static quantization (calibrate on training spectra)
class Calib(CalibrationDataReader):
def __init__(self, data, n=300):
self.it = iter([{"spectrum": data[i:i + 1]} for i in range(n)])
def get_next(self):
return next(self.it, None)
quantize_static(FP32, INT8, Calib(Xtr), quant_format=QuantFormat.QDQ,
weight_type=QuantType.QInt8, activation_type=QuantType.QInt8,
per_channel=False)
fp32_kb = os.path.getsize(FP32) / 1024
int8_kb = os.path.getsize(INT8) / 1024
print(f"[tinyml] fp32 onnx: {fp32_kb:.1f} KB int8 onnx: {int8_kb:.1f} KB "
f"({fp32_kb / int8_kb:.1f}x smaller)")
def evaluate(path):
sess = ort.InferenceSession(path, providers=["CPUExecutionProvider"])
logits = sess.run(None, {"spectrum": Xte})[0]
acc = (logits.argmax(1) == yte).mean()
one = Xte[:1]
for _ in range(50):
sess.run(None, {"spectrum": one})
t = time.perf_counter()
for _ in range(3000):
sess.run(None, {"spectrum": one})
us = (time.perf_counter() - t) / 3000 * 1e6
return acc, us
fp32_acc, fp32_us = evaluate(FP32)
int8_acc, int8_us = evaluate(INT8)
print(f"[tinyml] accuracy fp32 {fp32_acc:.3f} int8 {int8_acc:.3f} "
f"drop {100*(fp32_acc-int8_acc):+.2f} pts")
print(f"[tinyml] latency fp32 {fp32_us:.1f} us int8 {int8_us:.1f} us")
print(f"[tinyml] weight footprint at int8: ~{n_params} bytes ({n_params/1024:.1f} KB)")
fig, ax = plt.subplots(1, 2, figsize=(10, 4.2))
ax[0].bar(["fp32", "int8"], [fp32_kb, int8_kb], color=["#1e88e5", "#e53935"])
ax[0].set_ylabel("ONNX model size (KB)")
ax[0].set_title(f"Model size: {fp32_kb/int8_kb:.1f}x smaller at int8")
for i, v in enumerate([fp32_kb, int8_kb]):
ax[0].text(i, v, f"{v:.1f} KB", ha="center", va="bottom")
ax[1].bar(["fp32", "int8"], [fp32_acc * 100, int8_acc * 100],
color=["#1e88e5", "#e53935"])
ax[1].set_ylabel("test accuracy (%)")
ax[1].set_ylim(0, 105)
ax[1].set_title("Accuracy barely moves")
for i, v in enumerate([fp32_acc * 100, int8_acc * 100]):
ax[1].text(i, v, f"{v:.1f}%", ha="center", va="bottom")
fig.tight_layout()
fig.savefig("uploads/2026/06/tinyml-quantization.png", dpi=130)
print("[tinyml] saved uploads/2026/06/tinyml-quantization.png")